









"Los datos de entrenamiento constan de una matriz compuesta de ejemplos (registros u observaciones almacenados en filas), cada uno de los cuales cuenta con un conjunto de características (variables o campos almacenados en columnas). Se espera que las características especificadas en el diseño experimental caractericen los patrones de los datos. A pesar de que muchos de los campos de datos sin procesar se pueden incluir directamente en el conjunto de características seleccionado que se usa para entrenar un modelo, a menudo se da el caso de que se requiere construir características adicionales (diseñadas) a partir de las características existentes en los datos sin procesar para generar un conjunto de datos de entrenamiento mejorado." - Ingeniería de características en ciencia de datos
En resumen, la ingeniería de características consiste en actualizar o crear características pertinentemente a partir de los datos que tengamos sin procesar para mejorar la eficacia predictiva del algoritmo de aprendizaje.
Y vale mencionar que esta tarea debe desarrollarse con mucho cuidado ya que dependiendo del tipo de solución/modelo que estemos construyendo podría incluso convenir o perjudicar un mismo procedimiento.
Actualización de metadatos
Si el tipo de dato o variable establecido automáticamente para las columnas de nuestro conjunto de datos no es el adecuado, lo que tenemos que hacer es emplear el módulo Edit Metadata para corregirlo.

Combinación de conjuntos de datos (por columnas)
Si los datos vienen desde múltiples fuentes y los conjuntos de datos están relacionados por alguna columna, Azure Machine Learning Studio nos ofrece un par de alternativas para crear un único conjunto de datos:
Join Data Con este módulo podemos combinar dos conjuntos de datos usando JOIN de una forma muy similar a como se hace en SQL.

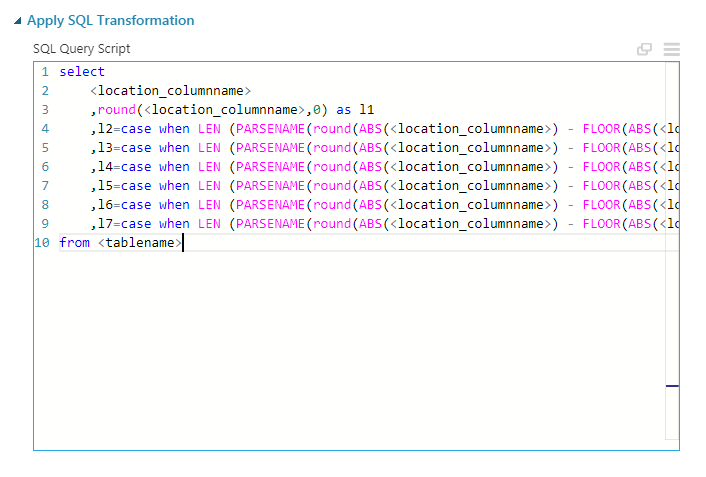
Apply SQL Transformation Con este módulo podemos combinar hasta tres conjuntos de datos usando SQLite.

Agrupación de valores de características (por filas)
Si lo que necesitamos es organizar valores de características en grupos podríamos emplear los módulos:
Group Categorical Values Este módulo combina varios valores de características categóricas en un solo nuevo nivel según se lo configure.

Group Data into Bins Este módulo permite agrupar valores continuos en "contenedores" o categorías a través de diferentes métodos.

Transformación de valores o construcción de características
Según las circunstancias, necesitaremos manipular los valores para que puedan ser procesados sin que generen inconvenientes. Azure Machine Learning Studio ofrece muchas opciones y en esta ocasión veremos solo un par:
Normalize Data El objetivo de la normalización es cambiar los valores continuos en el conjunto de datos para usar una escala común, sin distorsionar las diferencias en los rangos de valores o perder información. Por ejemplo, supongamos que un conjunto de datos de entrada contiene una columna con valores que van de 0 a 1, y otra columna con valores que van de 10,000 a 100,000. La gran diferencia en la escala de los números podría causar problemas cuando se intenten combinar los valores como características durante el modelado.

Feature Hashing Este módulo convierte los valores arbitrarias de texto en índices. En lugar de asociar cada característica de texto (palabras/frases) a un índice determinado, este método funciona mediante la aplicación de una función de hash a las características y el uso de sus valores de hash como índices directamente.

Apply SQL Transformation Este módulo nos permite generar nuevas columnas apoyándonos de las funciones SQLite disponibles.
Generación de características basadas en recuentos

Generación de características de discretización

Desplegando características desde una sola columna
Selección o reducción automática de características
Azure Machine Learning nos puede ayudar a determinar que características en un conjunto de datos tienen la mayor capacidad predictiva.
Filter Based Feature Selection Este módulo aplica pruebas estadísticas a las variables contenidas en el conjunto de datos y califica las mejores columnas en base a cual podría contener las más altas capacidades predictivas.

Principal Component Analysis El análisis de componentes principales es una técnica que se utiliza para enfatizar la variación y resaltar patrones fuertes en un conjunto de datos. De esta manera se puede reducir el número de columnas en un conjunto de datos y a menudo también se utiliza para facilitar la exploración y visualización de datos.


No hay comentarios.:
Publicar un comentario